机器学习 (ML) 是人工智能 (AI) 的一个子集,涉及使用算法和统计模型使计算机系统能够从数据中学习并随着时间的推移提高特定任务的性能,而无需进行显式编程。它涉及将大量数据输入到自动学习数据模式的算法中。机器学习有着广泛的应用,它正在迅速改变我们与技术交互和解决复杂问题的方式。
尽管机器学习算法得到广泛使用,但它仍可能遇到各种影响其性能和准确性的经典问题。几起有关训练数据或测试数据不足、有偏见的丑闻成为头条新闻。荷兰税务局、大众汽车的“柴油门”和亚马逊招聘软件的丑闻强烈提醒我们,在没有适当保障措施的情况下使用自动化系统可能会导致灾难性后果,特别是在世界各地的政府和企业越来越依赖算法和技术的情况下。人工智能可以简化他们的流程。
机器学习算法在多种情况下可能会出错,但在最好的情况下,这些错误是在算法设计过程中识别出来的。过度拟合、欠拟合和特征选择偏差是构建机器学习算法时的常见问题。当模型学习训练数据中的噪声并且不能很好地推广到新数据时,就会发生过度拟合。欠拟合意味着模型太简单,无法捕获数据中的潜在模式。当使用根据训练数据的性能选择的特征子集构建模型时,就会出现特征选择可能无法很好地推广到新数据。
机器学习算法还可能对异常值以及不平衡或过时的训练和测试数据集敏感。解决这些经典问题对于创建准确可靠的机器学习模型至关重要,这些模型可以提供有价值的见解和预测。
机器学习算法是如何创建的
尽管机器学习是人们关注的焦点,但如果不了解它们的创建过程,就很难理解这些算法的诞生。通常,数据科学家负责创建机器学习算法。数据科学是一个多学科领域,结合了统计、数学和计算工具,从数据中提取见解和知识。数据科学是一个更广泛的术语,包括各种处理数据的技术和方法。机器学习是这些技术的子集,专门专注于构建算法和模型。
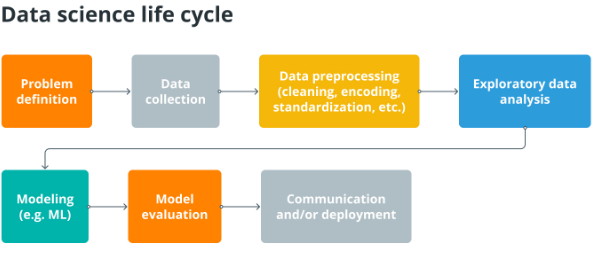
数据科学生命周期这些步骤通常包括定义问题、收集和清理数据、探索数据、基于假设开发模型、测试和验证模型以及将结果传达给利益相关者。在整个过程中,数据科学家使用各种工具和技术(包括统计分析、机器学习和数据可视化)来提取和传达有意义的见解并识别数据中的模式。
步骤并不是一成不变的。它们还强烈依赖于应用领域。例如,在学术环境中,模型评估之后就是结果的交流和传播。与此同时,在生产中,评估之后是部署、监控和维护。在商业环境中,它几乎不是一个线性过程,而是一系列的重复。
机器学习在建模步骤中发挥着重要作用。建模是指使用数据构建现实世界系统或现象的数学表示的过程。建模的目标是学习数据中的模式、关系和趋势。建模通常涉及选择适当的算法及其相关特征以及调整模型的超参数。使用各种指标评估模型的性能,并迭代地改进模型,直到获得令人满意的性能。
ML 模型选择涉及的步骤
数据科学生命周期的步骤也经常被视为机器学习的一部分,因为它们对于构建机器学习算法是不可避免的。然而,建模本身还包括子步骤,例如特征工程、分割数据、选择模型、调整超参数和评估型模选不仅基于需要回答的问题,还基于可用数据的性质。某些特征在模型选择中很重要,例如特征的数量、分类或数值变量的存在以及数据分布。某些算法可能更适合特定的数据类型或分布。
正确的数据预处理和解释性数据分析对于任何统计建模都至关重要,因为专家通过这些步骤发现特征。它们还提供了在适当的算法之间进行选择所需的信息。机器学习有两种主要类型的算法:监督算法和无监督算法。在监督机器学习中,模型根据标记数据进行训练,而在无监督机器学习中,模型从未标记数据中学习模式。请参阅下面的一些 ML 模型示例。

声明:本文所述观点并非519TGY链上之家的立场,并不构成对购买、持有或出售任何数字资产(包括加密货币、硬币和代币)或进行任何投资活动的邀约或建议,本文仅供参考。投资存在风险,请自行评估。转载需注明来源,违者必究!